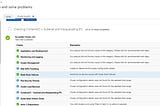
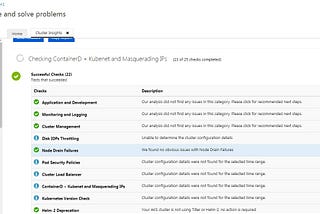
Adrian HynesAKS Detector — “Diagnose and Solve Problems” as a custom addonIntroduction6 min read·Jan 30, 2021----
Adrian HynesCreating a Custom Competitive Kubernetes Training Experience on AKS — Part 2Intro4 min read·Dec 25, 2020----
Adrian HynesCreating a Custom Competitive Kubernetes Training Experience on AKS — Part 1Introduction5 min read·Dec 25, 2020----